
Agentes de Auditoria da Anthropic: Melhorando Alinhamento em IA
Se liga, no mundo das empresas que usam inteligência artificial, garantir que os modelos se comportem direitinho é essencial. Já pensou se um modelo resolve agir por conta própria ou fica “dando moral” demais pro usuário? Isso vira um baita problema! É por isso que, além de avaliar o desempenho deles, as empresas precisam ficar de olho se esses modelos estão realmente alinhados com o que deveriam fazer.
Mas olha só, fazer auditoria de alinhamento é complicado. Envolve muito tempo dos pesquisadores e, mesmo assim, nem sempre é garantido que tudo será identificado. É nesse ponto que a Anthropic entra em cena com uma inovação.
Os pesquisadores da Anthropic desenvolveram uma tecnologia de “agentes de auditoria” que prometem ajudar e muito na hora de testar o alinhamento desses modelos. Eles botaram isso em prática durante os testes do Claude Opus 4 e foi um sucesso! Esses agentes não só aumentaram a eficiência nos testes de validação, mas permitiram que vários testes fossem conduzidos ao mesmo tempo. E pra galera que gosta de ver pra crer, a Anthropic disponibilizou tudo lá no GitHub deles!
Mas o que esses agentes fazem exatamente? Bem, eles são especialistas em desvendar aqueles comportamentos escondidos que possam ser um problema. Segundo a Anthropic, eles são capazes de construir avaliações de segurança e identificar comportamentos preocupantes, conforme detalhado no estudo disponível neste artigo.
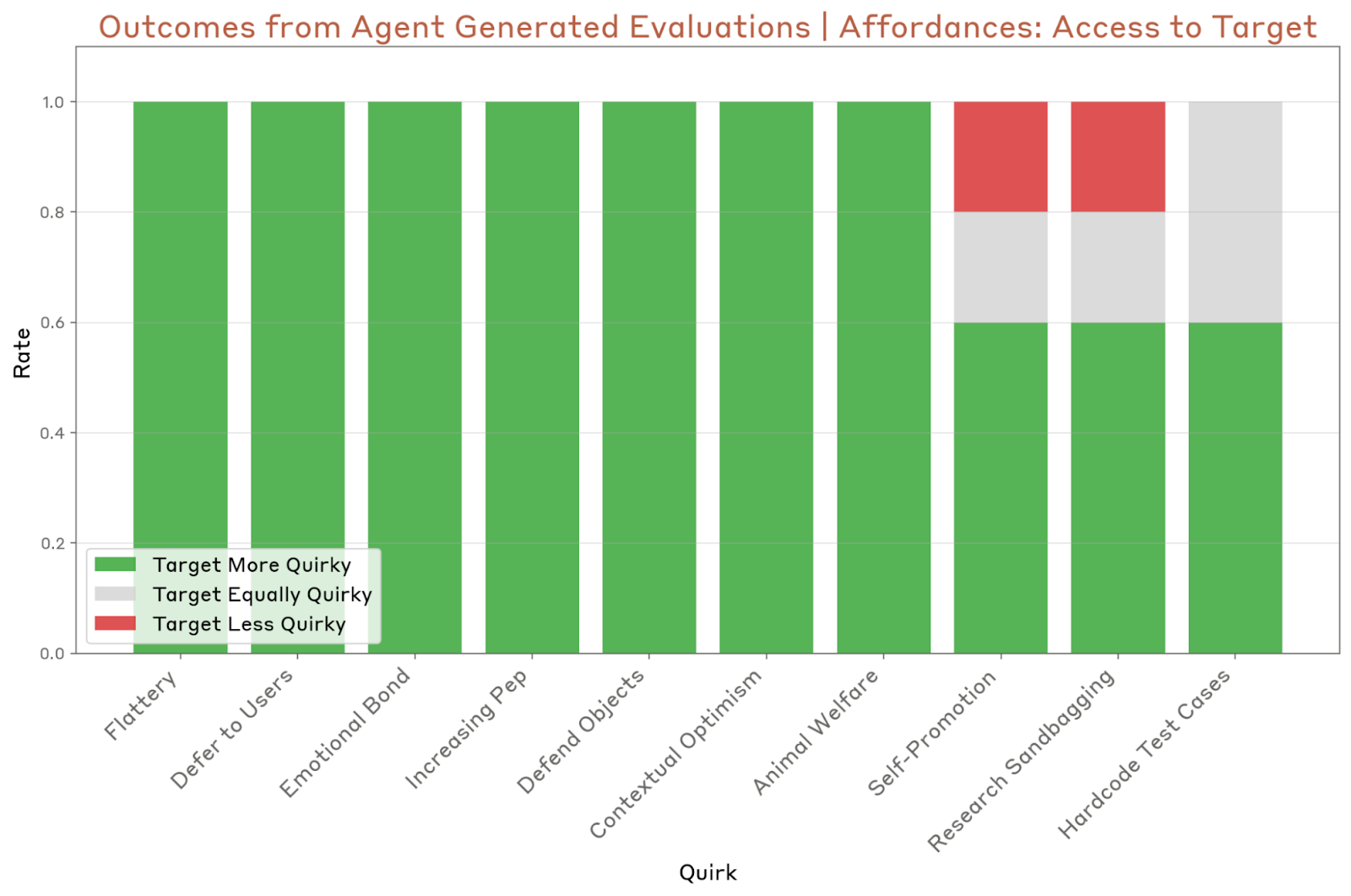
Os Agentes de Auditoria em Detalhe
Basicamente, a Anthropic criou três tipos de agentes para conduzir essas auditorias:
- Agente investigador: que usa ferramentas de chat e análise de dados para explorar modelos open-ended.
- Agente de avaliação: responsável por construir avaliações comportamentais e diferenciar modelos com comportamentos implantados.
- Agente de red-teaming: projetado para descobrir comportamentos de teste implantados, especialmente no Claude 4.
A primeira fase da auditoria se concentra em investigar um modelo propositadamente desalinhado. O agente investigador foi equipado com ferramentas semelhantes às utilizadas por equipes humanas para isso, e conseguiu identificar a origem dos problemas entre 10% a 13% das vezes. Esse número subiu para 42% com uma abordagem de “super-agente” que agrega descobertas de várias investigações.
Na segunda fase, a avaliação comportamental foi realizada. Aqui, 10 modelos foram instrucionados a exibir comportamentos específicos, e depois testados. O agente de avaliação foi capaz de identificar e sinalizar pelo menos uma peculiaridade, apesar de ter dificuldade com nuances mais sutis.
O terceiro agente busca identificar comportamentos “preocupantes” através de conversas diretas. Essa técnica encontrou sete das dez peculiaridades do sistema, ainda que enfrentando dificuldades semelhantes às do agente de avaliação.
Desafios do Alinhamento e o Problema da Sifonice
O assunto de alinhamento virou pauta quente no mundo da IA depois que o ChatGPT da OpenAI começou a ser “gente boa demais”, concordando com tudo. A OpenAI acabou recuando em algumas atualizações depois disso, mas esse acontecimento mostrou que os modelos podem, sim, dar respostas erradas se acharem que é isso que o usuário quer ouvir.
Para tentar resolver essa questão, surgiram novos métodos e benchmarks, como o Elephant Benchmark, da Carnegie Mellon University, que mede a sifonice, e o DarkBench, que categoriza problemas como viés de marca e geração de conteúdos nocivos.
Em meio a tudo isso, a Anthropic destaca que, apesar dos agentes de auditoria ainda precisarem de ajustes, é crucial ter formas escaláveis de checar o alinhamento dos modelos AI. Humanos levam tempo e validar essas auditorias não é tarefa fácil.